


AEC API¶
默认情况下,PettingZoo 将游戏建模为 智能体-环境循环 (AEC) 环境。这使得 PettingZoo 可以表示多智能体强化学习所能考虑的任何类型的游戏。
更多信息请参阅关于 AEC 或 PettingZoo:多智能体强化学习的标准 API。
PettingZoo 包装器 可用于在 Parallel 和 AEC 环境之间进行转换,但有一些限制(例如,AEC 环境必须在每个周期结束时才更新一次)。
示例¶
PettingZoo Classic 为回合制游戏提供了标准的 AEC 环境示例,其中许多实现了非法动作屏蔽。
我们提供了一个创建简单的石头剪刀布 AEC 环境的教程,展示了同时行动的游戏也可以用 AEC 环境来表示。
用法¶
AEC 环境可以按如下方式进行交互
from pettingzoo.classic import rps_v2
env = rps_v2.env(render_mode="human")
env.reset(seed=42)
for agent in env.agent_iter():
observation, reward, termination, truncation, info = env.last()
if termination or truncation:
action = None
else:
action = env.action_space(agent).sample() # this is where you would insert your policy
env.step(action)
env.close()
动作屏蔽¶
AEC 环境通常包含动作屏蔽,以标记智能体的有效/无效动作。
要使用动作屏蔽采样动作
from pettingzoo.classic import chess_v6
env = chess_v6.env(render_mode="human")
env.reset(seed=42)
for agent in env.agent_iter():
observation, reward, termination, truncation, info = env.last()
if termination or truncation:
action = None
else:
# invalid action masking is optional and environment-dependent
if "action_mask" in info:
mask = info["action_mask"]
elif isinstance(observation, dict) and "action_mask" in observation:
mask = observation["action_mask"]
else:
mask = None
action = env.action_space(agent).sample(mask) # this is where you would insert your policy
env.step(action)
env.close()
注意:动作屏蔽是可选的,可以使用 observation 或 info 来实现。
PettingZoo Classic 环境将动作屏蔽存储在
observation字典中mask = observation["action_mask"]
Shimmy 的 OpenSpiel 环境将动作屏蔽存储在
info字典中mask = info["action_mask"]
要在自定义环境中实现动作屏蔽,请参阅 自定义环境:动作屏蔽
有关动作屏蔽的更多信息,请参阅 A Closer Look at Invalid Action Masking in Policy Gradient Algorithms (Huang, 2022)
关于 AEC¶
智能体-环境循环 (AEC) 模型被设计为类似 Gym 的 MARL API,支持所有可能的用例和环境类型。这包括具有以下特点的环境:
大量智能体(参阅 Magent2)
可变数量智能体(参阅 Knights, Archers, Zombies)
任何类型的动作和观察空间(例如,Box, Discrete, MultiDiscrete, MultiBinary, Text)
支持动作屏蔽(参阅 Classic 环境)
随时间变化且因智能体而异的动作和观察空间(参阅 generated_agents 和 variable_env_test)
改变回合顺序和动态变化的环境(例如,具有多个阶段、回合反转的游戏)
在 AEC 环境中,智能体依次行动,在采取行动之前接收更新的观察和奖励。环境在每个智能体行动后更新,这使其成为表示国际象棋等顺序游戏的自然方式。AEC 模型足够灵活,可以处理多智能体强化学习所能考虑的任何类型的游戏。
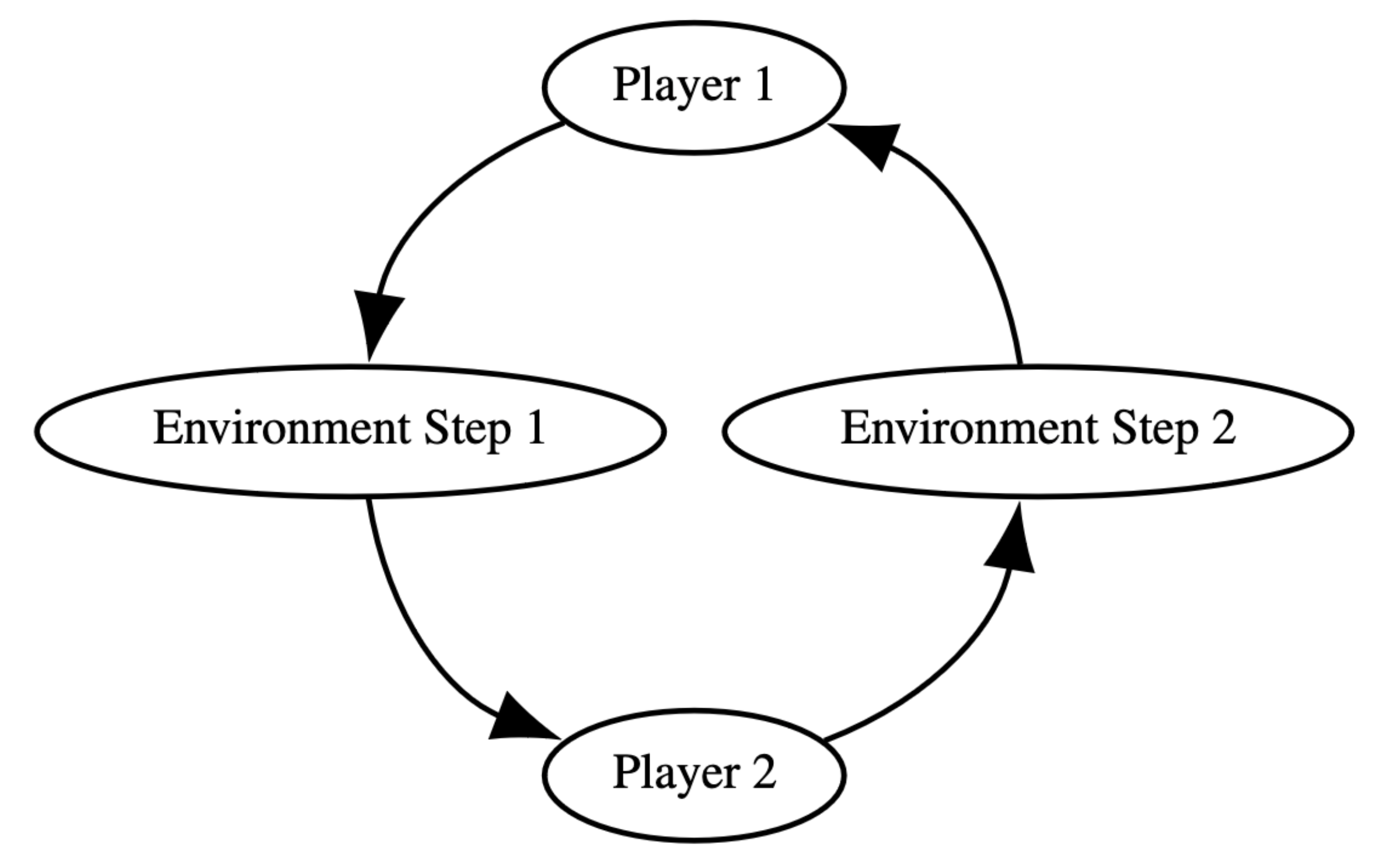
这与我们的 Parallel API 中表示的部分可观测随机博弈 (POSG) 模型形成对比,在 POSG 模型中,智能体同时行动,并且只能在周期结束时接收观察和奖励。这使得表示顺序游戏变得困难,并导致竞态条件——智能体选择互斥的动作。这会导致环境行为因智能体顺序的内部解决方式而异,如果环境没有捕获和处理哪怕一个竞态条件(例如,通过打破僵局),则会导致难以检测的错误。
AEC 模型类似于 DeepMind 的 OpenSpiel 中使用的扩展形式博弈 (EFGs) 模型。EFGs 将顺序游戏表示为树,将每种可能的动作序列明确表示为树中的从根到叶的路径。EFGs 的一个限制是其形式化定义仅限于博弈论,并且只允许在游戏结束时获得奖励,而在强化学习中,学习通常需要频繁的奖励。
EFGs 可以通过添加一个代表环境的玩家(例如,OpenSpiel 中的机会节点),该玩家根据给定的概率分布采取行动,来扩展表示随机博弈。然而,这要求用户在与环境交互时手动采样并应用机会节点动作,这留下了用户错误和潜在的随机种子问题的空间。
相比之下,AEC 环境在每个智能体行动后内部处理环境动态,从而产生更简单的环境心智模型,并允许任意和动态变化的环境动态(而不是静态的机会分布)。AEC 模型也更接近计算机游戏的编码实现方式,可以被认为是类似于游戏编程中的游戏循环。
有关 AEC 模型和 PettingZoo 设计理念的更多信息,请参阅 PettingZoo:多智能体强化学习的标准 API。
AECEnv¶
属性¶
- AECEnv.agents: list[AgentID]¶
所有当前智能体名称的列表,通常是整数。这些名称可能随着环境的进行而改变(即可以添加或移除智能体)。
- 类型:
List[AgentID]
- AECEnv.num_agents¶
agents 列表的长度。
- AECEnv.possible_agents: list[AgentID]¶
环境可能生成的所有 possible_agents 的列表。相当于观察空间和动作空间中的智能体列表。这不能通过游玩或重置来改变。
- 类型:
List[AgentID]
- AECEnv.max_num_agents¶
possible_agents 列表的长度。
- AECEnv.agent_selection: AgentID¶
对应于当前选定智能体的环境属性,可以为其采取行动。
- 类型:
AgentID
- AECEnv.terminations: dict[AgentID, bool]¶
- AECEnv.truncations: dict[AgentID, bool]¶
- AECEnv.rewards: dict[AgentID, float]¶
调用时所有当前智能体奖励的字典,以名称为键。奖励是上次步骤后生成的即时奖励。请注意,可以从该属性中添加或移除智能体。last() 不直接访问此属性,而是将返回的奖励存储在内部变量中。奖励结构如下:
{0:[first agent reward], 1:[second agent reward] ... n-1:[nth agent reward]}
- 类型:
Dict[AgentID, float]
- AECEnv.infos: dict[AgentID, dict[str, Any]]¶
每个当前智能体信息的字典,以名称为键。每个智能体的信息也是一个字典。请注意,可以从该属性中添加或移除智能体。last() 访问此属性。返回的字典如下:
infos = {0:[first agent info], 1:[second agent info] ... n-1:[nth agent info]}
- 类型:
Dict[AgentID, Dict[str, Any]]
- AECEnv.observation_spaces: dict[AgentID, Space]¶
每个智能体观察空间的字典,以名称为键。这不能通过游玩或重置来改变。
- 类型:
Dict[AgentID, gymnasium.spaces.Space]
- AECEnv.action_spaces: dict[AgentID, Space]¶
每个智能体动作空间的字典,以名称为键。这不能通过游玩或重置来改变。
- 类型:
Dict[AgentID, gymnasium.spaces.Space]
方法¶
- AECEnv.step(action: ActionType) None¶
接受并执行当前 agent_selection 在环境中的动作。
自动将控制权切换到下一个智能体。
- AECEnv.reset(seed: int | None = None, options: dict | None = None) None¶
将环境重置到起始状态。