


追逐¶
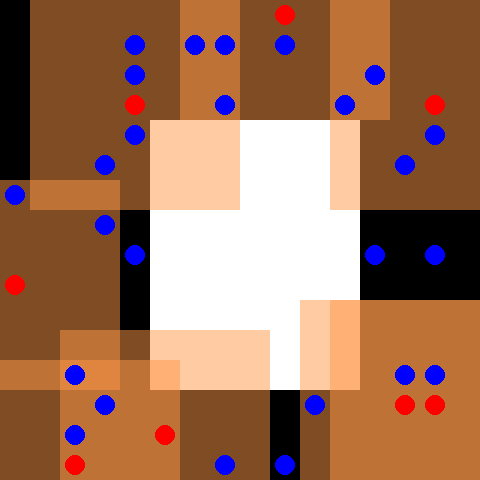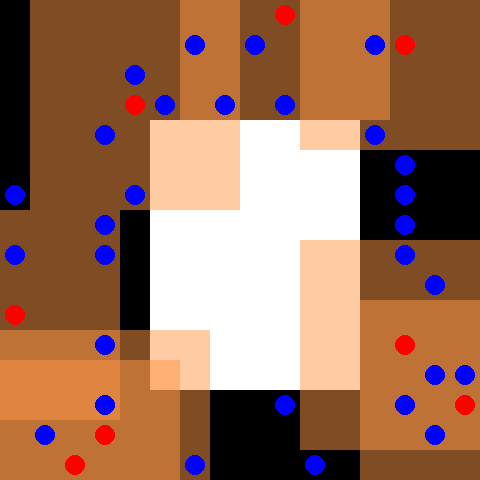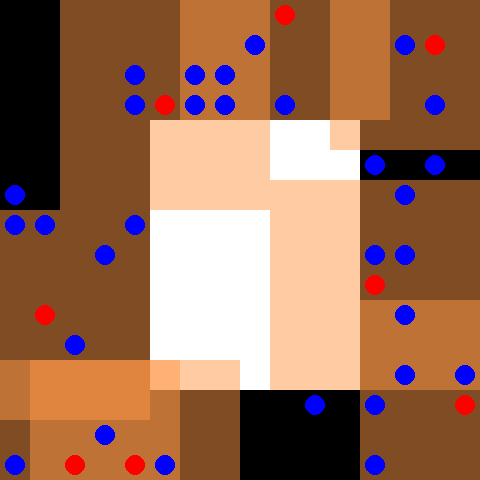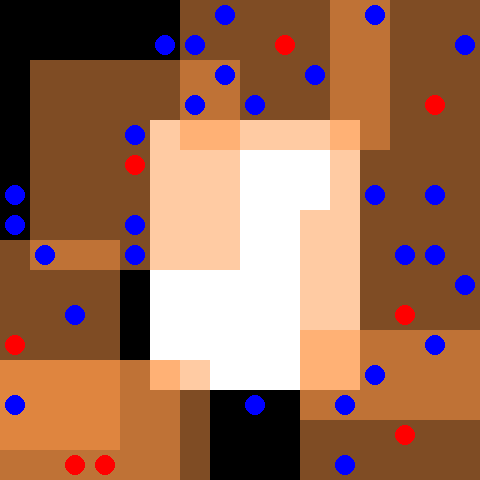
该环境是 SISL 环境 的一部分。请先阅读该页面以获取一般信息。
导入 |
|
|---|---|
动作 |
离散 |
Parallel API |
是 |
手动控制 |
是 |
智能体 |
|
智能体 |
8 (+/-) |
动作形状 |
(5) |
动作值 |
Discrete(5) |
观察形状 |
(7, 7, 3) |
观察值 |
[0, 30] |
默认情况下,30 个蓝色逃脱者智能体和 8 个红色追逐者智能体被放置在一个 16 x 16 的网格中,网格中心有一个白色障碍物。逃脱者随机移动,而追逐者受控制。每当追逐者完全包围一个逃脱者时,每个包围的智能体都会获得 5 的奖励,并且逃脱者从环境中移除。追逐者每次接触逃脱者时也会获得 0.01 的奖励。追逐者具有离散动作空间,包括上、下、左、右和停留。每个追逐者观察以自身为中心的 7 x 7 网格,这由红色追逐者智能体周围的橙色框表示。当所有逃脱者都被捕获或完成 500 个周期时,环境终止。请注意,此环境已应用了 PettingZoo 论文第 4.1 节中描述的奖励剪枝优化。
观察形状为完整的 (obs_range, obs_range, 3) 形式,其中第一个通道表示墙壁(值为 1),第二个通道表示每个坐标中的盟友数量,第三个通道表示每个坐标中的对手数量。
手动控制¶
使用“J”和“K”选择不同的追逐者。选定的追逐者可以使用方向键移动。
参数¶
pursuit_v4.env(max_cycles=500, x_size=16, y_size=16, shared_reward=True, n_evaders=30,
n_pursuers=8,obs_range=7, n_catch=2, freeze_evaders=False, tag_reward=0.01,
catch_reward=5.0, urgency_reward=-0.1, surround=True, constraint_window=1.0)
x_size, y_size: 环境世界空间的大小
shared_reward: 奖励是否应分配给所有智能体
n_evaders: 逃脱者数量
n_pursuers: 追逐者数量
obs_range: 智能体观察范围框的大小
n_catch: 捕获逃脱者所需的追逐者数量(包围)
freeze_evaders: 切换逃脱者是否可以移动
tag_reward: “标记”奖励,或作为单个逃脱者的奖励。
term_pursuit: 当一个或多个追逐者捕获逃脱者时添加的奖励
urgency_reward: 每一步添加到智能体的奖励
surround: 切换逃脱者是被包围时移除,还是当 n_catch 个追逐者位于逃脱者上方时移除
constraint_window: 智能体可以在环境世界中随机生成的位置框的大小(从中心计算,以比例单位表示)。默认为 1.0,表示可以在地图上的任何地方生成。值为 0 表示所有智能体在中心生成。
max_cycles: 在 max_cycles 步之后,所有智能体将返回 done
版本历史¶
v4: 改变奖励分配,修复集合错误,在渲染中添加智能体计数 (1.14.0)
v3: 观察空间错误修复 (1.5.0)
v2: 其他错误修复 (1.4.0)
v1: 各种修复和环境参数更改 (1.3.1)
v0: 初版发布 (1.0.0)
用法¶
AEC¶
from pettingzoo.sisl import pursuit_v4
env = pursuit_v4.env(render_mode="human")
env.reset(seed=42)
for agent in env.agent_iter():
observation, reward, termination, truncation, info = env.last()
if termination or truncation:
action = None
else:
# this is where you would insert your policy
action = env.action_space(agent).sample()
env.step(action)
env.close()
Parallel¶
from pettingzoo.sisl import pursuit_v4
env = pursuit_v4.parallel_env(render_mode="human")
observations, infos = env.reset()
while env.agents:
# this is where you would insert your policy
actions = {agent: env.action_space(agent).sample() for agent in env.agents}
observations, rewards, terminations, truncations, infos = env.step(actions)
env.close()
API¶
- class pettingzoo.sisl.pursuit.pursuit.raw_env(*args, **kwargs)[source]¶
-
- observation_space(agent: str)[source]¶
接收智能体并返回该智能体的观察空间。
对于相同的智能体名称,必须返回相同的值
默认实现是返回 observation_spaces 字典