


水世界¶
此环境是 SISL 环境 的一部分。请先阅读该页面以获取一般信息。
导入 |
|
|---|---|
动作空间 |
连续 |
Parallel API |
是 |
手动控制 |
否 |
智能体 |
|
智能体 |
5 |
动作形状 |
(2,) |
动作取值 |
[-0.01, 0.01] |
观察形状 |
(242,) |
观察取值 |
[-√2, 2*√2] |
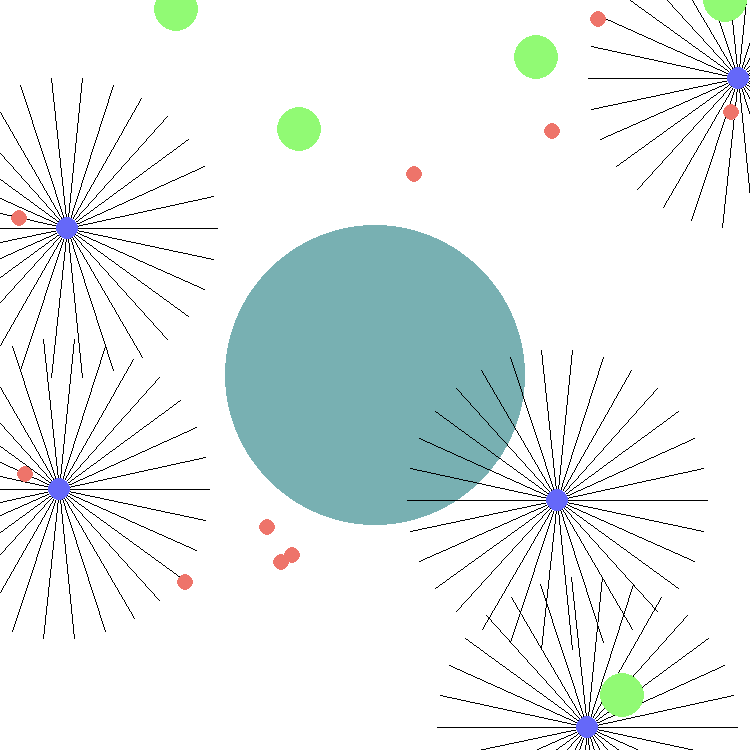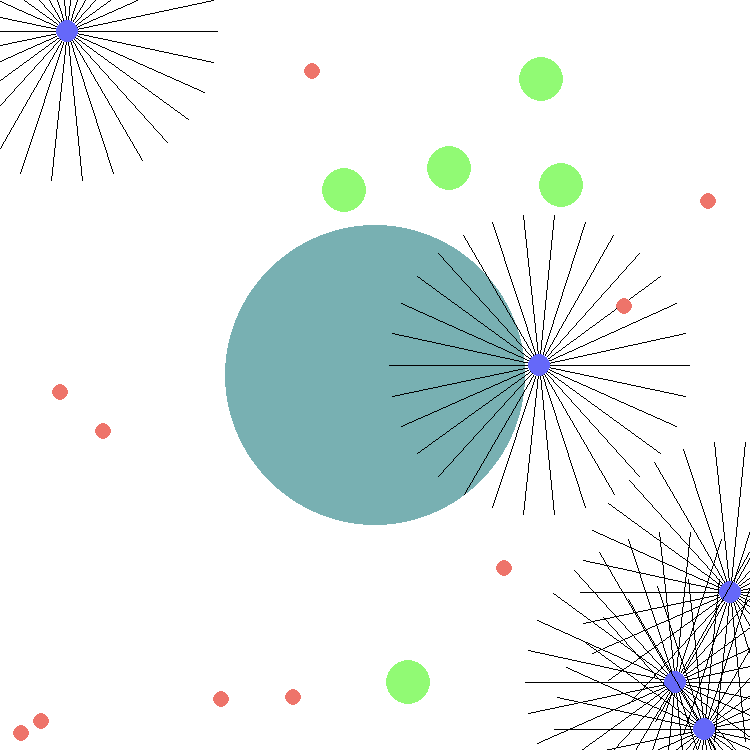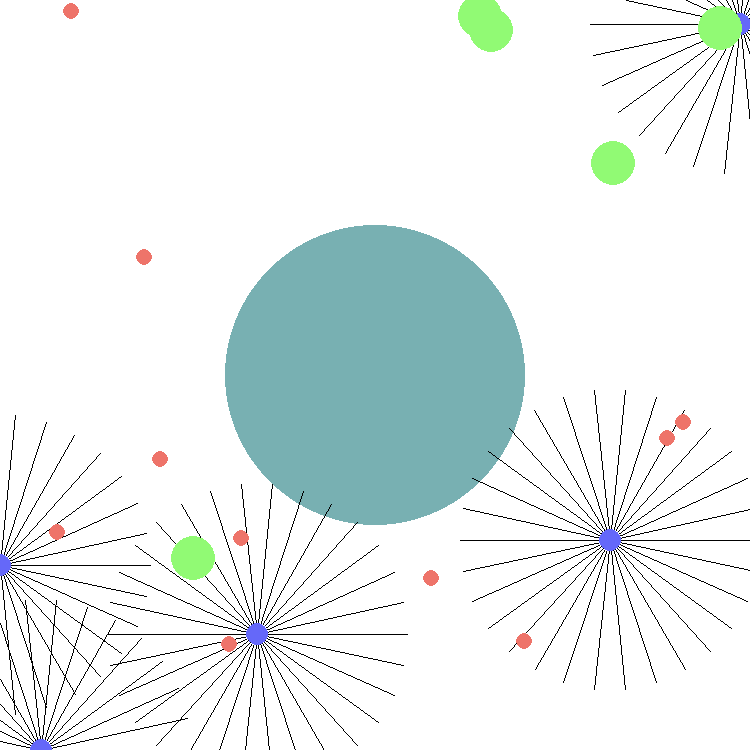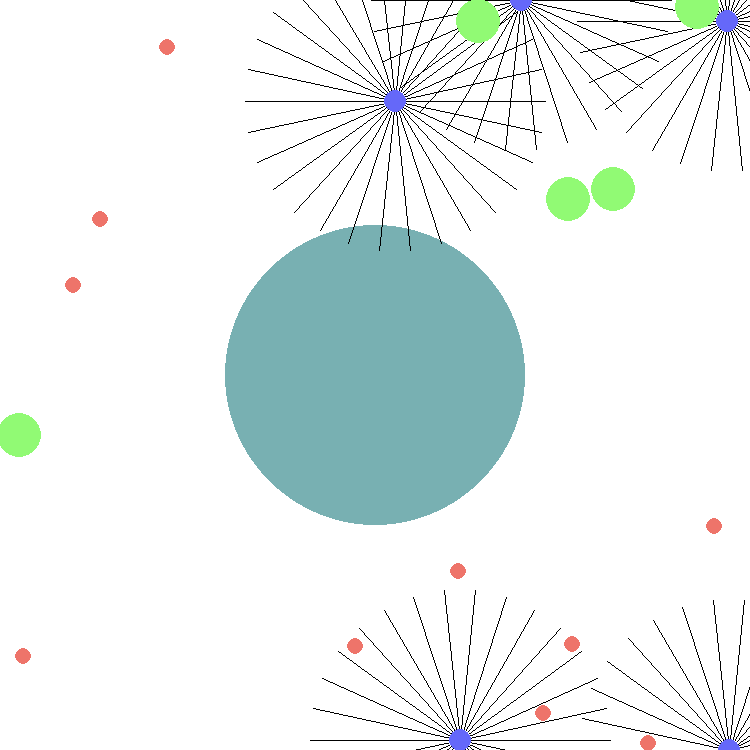
水世界模拟了古菌在其环境中导航并努力生存的过程。这些被称为“追逐者”的古菌试图在避开毒药的同时消耗食物。水世界中的智能体是追逐者,而食物和毒药属于环境。毒药的半径是追逐者半径的 0.75 倍,而食物的半径是追逐者半径的 2 倍。根据输入参数,多个追逐者可能需要协作来消耗食物,从而形成一种既合作又竞争的动态。类似地,奖励可以全局分配给所有追逐者,也可以局部应用于特定的追逐者。环境是一个连续的二维空间,每个追逐者的位置都有 x 和 y 值,范围都在 [0,1] 内。智能体无法越过 x 和 y 值的最小值和最大值处的边界。智能体通过选择一个推力向量来增加其当前速度。每个追逐者都有一些均匀分布的传感器,可以读取附近物体的速度和方向。这些信息在观察空间中报告,可用于导航环境。
观察空间¶
每个智能体的观察形状是一个长度大于 4 的向量,其长度取决于环境的输入参数。向量的总长度是每个传感器的特征数量乘以传感器数量,再加上两个分别表示追逐者是否与食物或毒药碰撞的元素。默认情况下,如果启用 speed_features,每个传感器的特征数量为 8,如果关闭 speed_features,则为 5。因此,如果启用 speed_features,观察形状的完整形式是 (8 × n_sensors) + 2。观察向量的元素取值范围是 [-1, 1]。
例如,默认情况下有 5 个智能体(紫色)、5 个食物目标(绿色)和 10 个毒药目标(红色)。每个智能体有 30 个范围有限的传感器(由黑线表示),用于检测附近的实体(食物和毒药目标),从而产生一个包含 242 个计算值的向量作为观察空间。这些值代表每个传感器感应到的距离和速度。在其范围内未感应到任何物体的传感器,其速度报告为 0,距离报告为 1。
与参考环境相比,此版本已修复,以防止物体飘出屏幕并永远丢失。
下表列出了启用 speed_features = True 时的观察空间
索引:[开始, 结束) |
描述 |
取值范围 |
|---|---|---|
0 到 n_sensors |
每个传感器的障碍物距离 |
[0, 1] |
n_sensors 到 (2 * n_sensors) |
每个传感器的边界距离 |
[0, 1] |
(2 * n_sensors) 到 (3 * n_sensors) |
每个传感器的食物距离 |
[0, 1] |
(3 * n_sensors) 到 (4 * n_sensors) |
每个传感器的食物速度 |
[-2*√2, 2*√2] |
(4 * n_sensors) 到 (5 * n_sensors) |
每个传感器的毒药距离 |
[0, 1] |
(5 * n_sensors) 到 (6 * n_sensors) |
每个传感器的毒药速度 |
[-2*√2, 2*√2] |
(6 * n_sensors) 到 (7 * n_sensors) |
每个传感器的追逐者距离 |
[0, 1] |
(7 * n_sensors) 到 (8 * n_sensors) |
每个传感器的追逐者速度 |
[-2*√2, 2*√2] |
8 * n_sensors |
指示智能体是否与食物碰撞 |
{0, 1} |
(8 * n_sensors) + 1 |
指示智能体是否与毒药碰撞 |
{0, 1} |
下表列出了禁用 speed_features = False 时的观察空间
索引:[开始, 结束) |
描述 |
取值范围 |
|---|---|---|
0 - n_sensors |
每个传感器的障碍物距离 |
[0, 1] |
n_sensors - (2 * n_sensors) |
每个传感器的边界距离 |
[0, 1] |
(2 * n_sensors) - (3 * n_sensors) |
每个传感器的食物距离 |
[0, 1] |
(3 * n_sensors) - (4 * n_sensors) |
每个传感器的毒药距离 |
[0, 1] |
(4 * n_sensors) - (5 * n_sensors) |
每个传感器的追逐者距离 |
[0, 1] |
(5 * n_sensors) |
指示智能体是否与食物碰撞 |
{0, 1} |
(5 * n_sensors) + 1 |
指示智能体是否与毒药碰撞 |
{0, 1} |
动作空间¶
智能体有一个连续的动作空间,表示为一个包含 2 个元素的向量,对应于水平和垂直推力。取值范围取决于 pursuer_max_accel。动作取值必须在范围 [-pursuer_max_accel, pursuer_max_accel] 内。如果此动作向量的幅度超过 pursuer_max_accel,它将被按比例缩小到 pursuer_max_accel。此速度向量会添加到古菌的当前速度上。
智能体动作空间: [horizontal_thrust, vertical_thrust]
奖励¶
当多个智能体(取决于 n_coop)一起捕获食物时,每个智能体获得 food_reward 的奖励(食物不会被摧毁)。它们因接触食物获得 encounter_reward 的塑形奖励,因接触毒药获得 poison_reward 的奖励,并且每采取一个动作,还会获得 thrust_penalty x ||action|| 的奖励,其中 ||action|| 是动作速度的欧几里得范数。所有这些奖励也根据 local_ratio 进行分配,其中按 local_ratio 缩放的奖励(局部奖励)应用于产生奖励的智能体,而按智能体数量平均后的奖励(全局奖励)按 (1 - local_ratio) 缩放并应用于所有智能体。默认情况下,环境运行 500 帧。
参数¶
waterworld_v4.env(n_pursuers=5, n_evaders=5, n_poisons=10, n_coop=2, n_sensors=20,
sensor_range=0.2,radius=0.015, obstacle_radius=0.2, n_obstacles=1,
obstacle_coord=[(0.5, 0.5)], pursuer_max_accel=0.01, evader_speed=0.01,
poison_speed=0.01, poison_reward=-1.0, food_reward=10.0, encounter_reward=0.01,
thrust_penalty=-0.5, local_ratio=1.0, speed_features=True, max_cycles=500)
n_pursuers:追逐古菌(智能体)的数量
n_evaders:食物对象的数量
n_poisons:毒药对象的数量
n_coop:必须同时接触食物才能消耗食物的追逐古菌(智能体)数量
n_sensors:所有追逐古菌(智能体)上的传感器数量
sensor_range:所有追逐古菌(智能体)上传感器树突的长度
radius:古菌基本半径。追逐者:半径,食物:半径的 2 倍,毒药:半径的 3/4 倍
obstacle_radius:障碍物半径
obstacle_coord:障碍物坐标。可以设置为 None 以使用随机位置
pursuer_max_accel:追逐古菌最大加速度(最大动作大小)
pursuer_speed:追逐者(智能体)最大速度
evader_speed:食物速度
poison_speed:毒药速度
poison_reward:追逐者消耗毒药对象获得的奖励(通常为负)
food_reward:追逐者消耗食物对象获得的奖励
encounter_reward:追逐者与食物对象碰撞获得的奖励
thrust_penalty:用于惩罚大动作的负奖励的缩放因子
local_ratio:奖励在局部和全局分配的比例
speed_features:切换追逐古菌(智能体)传感器是否检测其他物体和古菌的速度
max_cycles:在 max_cycles 步之后,所有智能体将返回 done
v4:重大重构 (1.22.0)
v3:重构和重大错误修复 (1.5.0)
v2:杂项错误修复 (1.4.0)
v1:各种修复和环境参数更改 (1.3.1)
v0:初始版本发布 (1.0.0)
用法¶
AEC¶
from pettingzoo.sisl import waterworld_v4
env = waterworld_v4.env(render_mode="human")
env.reset(seed=42)
for agent in env.agent_iter():
observation, reward, termination, truncation, info = env.last()
if termination or truncation:
action = None
else:
# this is where you would insert your policy
action = env.action_space(agent).sample()
env.step(action)
env.close()
Parallel¶
from pettingzoo.sisl import waterworld_v4
env = waterworld_v4.parallel_env(render_mode="human")
observations, infos = env.reset()
while env.agents:
# this is where you would insert your policy
actions = {agent: env.action_space(agent).sample() for agent in env.agents}
observations, rewards, terminations, truncations, infos = env.step(actions)
env.close()
API¶
- class pettingzoo.sisl.waterworld.waterworld.raw_env(*args, **kwargs)[source]¶
-
- observation_space(agent)[source]¶
接受智能体并返回该智能体的观察空间。
对于相同的智能体名称,必须返回相同的值
默认实现是返回 observation_spaces 字典